在数字化浪潮席卷全球的今天,数据已成为驱动社会进步和企业发展的核心生产要素。从个人照片、视频到企业文档、海量日志,数据的种类和规模正以前所未有的速度增长。传统的文件系统与块存储架构在应对海量非结构化数据时,逐渐显露出扩展性、成本和管理上的瓶颈。正是在这样的背景下,分布式对象存储应运而生,并迅速崛起为现代数据处理与存储服务的基石。
一、 何谓分布式对象存储?
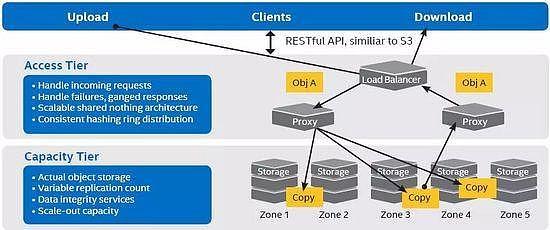
分布式对象存储是一种数据存储架构,它将数据作为独立的“对象”进行管理,每个对象都包含数据本身、可扩展的元数据以及一个全局唯一的标识符。这些对象被扁平地存放在一个巨大的、可跨越多个物理节点的存储池中,而非传统的目录树结构。其“分布式”特性意味着存储集群由成百上千个标准商用服务器组成,通过软件将它们的硬盘资源整合为一个统一、高可用的存储服务。这彻底改变了数据存储的范式:从管理物理磁盘和文件路径,转变为通过简单的API(如HTTP RESTful API)来存取由唯一ID标识的数据对象。
二、 核心优势:应对现代数据挑战
分布式对象存储之所以成为云时代和数据湖架构的首选,源于其与生俱来的几大核心优势:
- 近乎无限的扩展性:采用扁平命名空间和分布式架构,理论上可以通过简单地增加节点来线性扩展存储容量和性能,轻松应对从TB到EB级别的数据增长。
- 高耐用性与可用性:数据并非单一副本存储。通过诸如纠删码或多副本复制等技术,数据被分散存储在多个节点甚至多个地理区域。即使部分硬件发生故障,数据也不会丢失,服务也不会中断,通常可提供11个9(99.999999999%)以上的数据持久性。
- 成本效益:基于通用的x86服务器硬件构建,避免了高端专用存储设备的高昂成本。其扩展模式允许按需增长,避免了过度预置。通过生命周期策略自动将冷数据迁移到更廉价的存储层,进一步优化总体拥有成本。
- 面向海量非结构化数据:完美适配图片、音视频、备份归档、日志文件等非结构化数据,这些正是当今数据增长的主要来源。
- 简单的访问与管理:提供标准的RESTful API(如S3兼容API),使得应用开发集成变得异常简单,并便于实现跨平台、跨地域的数据访问。
三、 数据处理与存储服务的深度融合
分布式对象存储不仅仅是一个被动的“数据仓库”,它正日益与数据处理服务深度融合,形成智能的数据平台。这主要体现在:
- 计算存储分离与协同:现代大数据和AI框架(如Spark、TensorFlow)可以直接从对象存储中读取数据进行分析和训练,实现了计算资源与存储资源的独立弹性伸缩。存储服务提供高带宽的数据供给,计算集群负责高效处理,二者通过高速网络协同工作。
- 内置的数据处理功能:许多先进的分布式对象存储系统开始集成“存储侧计算”能力。例如,用户可以在上传/下载对象时触发特定的数据处理函数(如图片缩略图生成、视频转码、内容审核等),而无需先将数据移动到计算集群。这减少了数据移动的开销,实现了近数据处理,大幅提升了效率。
- 数据湖的核心存储层:对象存储以其无限的扩展能力和对多种数据格式的原生支持,成为构建企业数据湖的理想底层存储。所有原始数据、处理后的数据以及分析结果都可以统一存放在对象存储中,供上层的计算引擎按需访问,打破了数据孤岛。
四、 典型应用场景
分布式对象存储已渗透到数字经济的方方面面:
- 云存储与备份归档:为公有云(如AWS S3, Azure Blob)提供基础服务,也是企业混合云备份和长期归档的经济之选。
- 内容存储与分发:存储网站、移动应用的静态内容(图片、CSS、JS),并与CDN结合实现全球高速分发。
- 大数据与分析平台:作为Hadoop、Spark等分析平台的底层存储,承载海量的日志、点击流、物联网传感器数据。
- 富媒体存储与处理:托管海量音视频文件,并与转码、流媒体服务结合,支撑视频点播、直播等应用。
- 原生云应用存储:为容器化、微服务架构的现代应用提供持久化、可共享的存储接口。
###
分布式对象存储通过其革命性的架构,解决了海量非结构化数据在存储、访问、管理和成本上的核心痛点。它已从一个单纯的存储系统,演变为一个集数据持久化、管理和智能处理于一体的综合性服务平台。在(下)篇中,我们将深入剖析其关键技术原理,如一致性哈希、纠删码、数据一致性模型,并探讨其与文件存储、块存储的差异及选型考量。
作为数据处理与存储服务的现代基石,理解分布式对象存储,无疑是打开云计算与大数据时代大门的一把关键钥匙。