在数据驱动决策的时代,企业数据量呈现爆炸式增长,传统的数据存储与处理架构在扩展性、成本与性能上面临严峻挑战。云上数据湖应运而生,成为整合多源、多格式海量数据,并支撑高级分析、机器学习等负载的理想平台。而数据湖的效能,很大程度上取决于其底层存储方案的性能与可靠性。JindoFS,作为阿里云开源的高性能数据湖存储方案,正以其卓越的设计,为云上大数据处理提供强劲的存储引擎。
一、JindoFS:定位与核心价值
JindoFS 是阿里云JindoData套件的核心组件之一,专为优化云上对象存储(如OSS)的大数据访问场景而设计。它并非一个独立的存储系统,而是一个智能的“加速层”或“缓存层”,位于计算集群(如E-MapReduce, ACK)与低成本、高可靠的云对象存储之间。其核心价值在于:
- 高性能:通过内存、SSD和本地HDD构建多层缓存体系,将热数据缓存在计算节点本地或近端,极大降低了访问延迟,使OSS能够提供近似HDFS的读写性能,满足了交互式查询、实时计算等低延迟需求。
- 云原生与成本优化:坚持“热数据加速,冷数据沉降”的原则。热数据在缓存中高速访问,冷数据自动沉降至OSS长期存储,实现了存储与计算的分离。用户无需为计算集群预置巨额存储容量,可按需弹性伸缩,显著降低了总体拥有成本(TCO)。
- 兼容性与生态无缝集成:完全兼容HDFS文件系统接口,现有的大数据应用(如Spark、Flink、Hive、Presto等)无需修改代码即可透明访问,实现了从传统Hadoop架构到云上数据湖架构的平滑迁移。
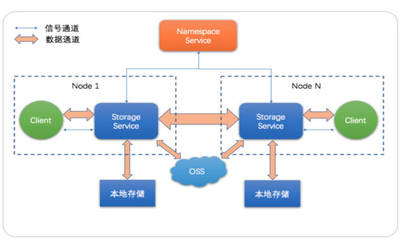
二、架构解析:智能缓存与命名空间服务
JindoFS 主要包含两大核心架构模式,以适应不同场景:
- 存储加速模式(Block模式):
- 核心思想:将OSS上的文件切割成固定大小的数据块(Block),并缓存在本地集群中。
- 工作流程:客户端首次读取数据时,从OSS拉取数据块并缓存在本地;后续访问相同或相邻数据时,可直接从高速缓存中读取,大幅提升I/O效率。写入时,数据先写入本地缓存,再异步持久化到OSS,保证高吞吐。
- 优势:缓存粒度细,适合随机读取和机器学习等迭代计算场景,缓存利用率高。
- 缓存模式(Namespace模式):
- 核心思想:在内存中维护一个独立的文件系统命名空间,并将文件数据缓存在本地。
- 工作流程:文件目录结构等元数据由JindoFS的元数据服务管理,文件数据则根据策略缓存在各计算节点。它更像一个独立的、基于缓存的文件系统,所有读写操作首先面向缓存系统。
- 优势:提供了完整的文件系统语义,更适合需要强一致性、频繁元数据操作(如列出目录)的场景。
三、作为数据处理与存储服务的实践
在实际的大数据流水线中,JindoFS 扮演着承上启下的关键角色:
- 数据接入与落地:来自日志、数据库、IoT设备的数据,可通过DataX、Flume、Kafka等工具直接写入JindoFS(后端为OSS),利用其缓存能力提升写入吞吐,并立即为下游计算可用。
- 交互式分析与即席查询:Presto、Spark SQL等引擎查询OSS中的数据时,通过JindoFS加速,能将首次分钟级的查询缩短到后续的秒级甚至亚秒级响应,极大提升了数据分析师的效率。
- 大规模批处理与机器学习:Spark、Flink进行ETL作业或模型训练时,需要反复读取训练数据。JindoFS的智能缓存避免了每次计算都从OSS远程拉取数据,将作业运行时间减少30%-70%不等,同时节省了跨网络流量成本。
- 数据管理与生命周期:结合OSS的存储分级(标准、低频、归档)和生命周期策略,JindoFS可以自动管理缓存数据的留存时间,形成“热-温-冷”数据的自动化流转,在性能和成本间取得最佳平衡。
四、与展望
JindoFS 巧妙地将本地高速存储的性能与云对象存储的无限扩展性和经济性结合起来,破解了云上数据湖“存算分离”架构下的性能瓶颈。它不仅是简单的缓存,更是一个智能的数据访问加速与编排服务。随着计算与存储进一步解耦、实时分析需求日益增长,JindoFS这类技术将成为构建高效、敏捷、低成本云原生数据湖的标配组件,持续赋能企业挖掘数据海洋中的深层价值。
对于寻求上云或优化现有云上大数据平台的企业而言,深入理解和合理部署JindoFS,是构建高性能数据处理管道、实现数据驱动业务飞跃的关键一步。